1. Row Level Compression: This type of compression will work on the row level of the data page.
a. Operations like changing the fixed length datatype to Variable length data type. For instance, Char(10) is a fixed length datatype and If we store “Venkat” as data. The space occupied by this name is 6 and remaining 4 spaces will be wasted in the legacy system. Whereas, In SQL Server 2008, it is utilised effectively. Only 6 spaces will be given to this variable.
b. Removal of Null value and zeros. These values will not be stored in the disk. Instead, they will have a reference in the CI Structure.
c. Reduce the amount of metadata used to store the row.
2. Page Level Compression: This compression will be effective in the page level.
a. This compression follows Row Level Compression. On top of that, Page level compression will work.
b. Prefix Compression - This compression will work on the column level. Repeated data will be removed and a reference will be stored in the Compression information (CI) structure which is located next to the page header.
c. Dictionary Compression – This compression will be implemented as a whole on the page. It will remove all the repeated data and a reference will be placed on the page.
How it works:
Considering, If you a user is requesting for a data. In that case, Relational Engine will take care of getting the request compile, parse and it will request the data from the Storage engine.
 Now, our data is in the compressed format. Storage engine will send the compressed data to the Buffer cache which in turn will take care of sending the data to relational engine in uncompressed format. Relational engine will do the modifications on the uncompressed data and it will send the same to buffer cache. Buffer cache will take care of compressing the data and have it for future use. In turn, it will send a copy to the Storage Engine.
Now, our data is in the compressed format. Storage engine will send the compressed data to the Buffer cache which in turn will take care of sending the data to relational engine in uncompressed format. Relational engine will do the modifications on the uncompressed data and it will send the same to buffer cache. Buffer cache will take care of compressing the data and have it for future use. In turn, it will send a copy to the Storage Engine.Advantages:
1. More data will be stored in the Buffer cache. So, no need to go and search in the disk which inturn reduce the I/O.
2. Disk space is highly reduced.
Disadvantages:
1. More CPU cycles will be used to decompress the data.
2. It will be a negative impact, if the data doesn’t have more null values, zeros and compact/exact data (Equivalent to the declared data type).
Cheers,
Venkatesan Prabu .J






























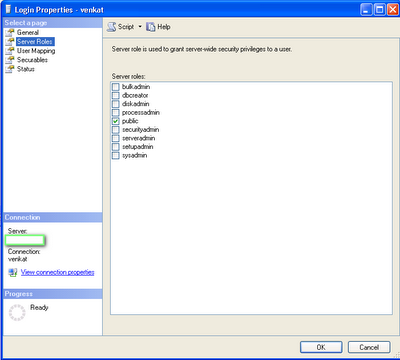
 The final page is status. It will define the current state of the user.
The final page is status. It will define the current state of the user.